
As of March of this year, approximately 42% of people who clicked through our social media posts landed on expired or closed job offers.
I run QualityAssuranceJobs.com, a website that aggregates software testing roles and promotes them on social media. And for someone actively looking for work in a tough market, it’s a frustrating dead end. For us – a community focused on getting QA jobs to the right people as quickly as possible – this meant that our social distribution was working against us.
The whole point is speed: get someone a new listing before the job ends. But we had outgrown the workflow that was supposed to make that happen, and the gap between “job goes live” and “job goes social” had become large enough to have a measurable impact on our community.
So we developed a workflow to fix the problem: Here’s what happened to our traffic when we did this.
We needed a change to our old setup
For a long time, our social sales were done through Zapier, and it served its purpose. Zapier makes a fantastic product and I have no idea how they keep track given the sheer number of integrations they support.
But our particular workflow had three moving parts, each with its own delay. It started with our publishing platform’s RSS feed, which was never designed to be real-time access to a live job board. Updates came as they came. Zapier polled this feed, causing more delay. And the Zapier-to-Buffer connection, our only connection to social networks, added even more.
Sometimes more than an hour passed between posting a job and posting it on social media. In the job market, an hour can mean the difference between a job opening still being open or someone else already filling the position. Additionally, I spent almost 10 hours a week checking, re-checking, and tracking down bugs. Things kept falling through, and so 42% of our social media clicks ended up on expired posts, ending up dead ends with the very real people who needed them.
Something had to change.
If someone, especially an experienced software developer, tells you to use code as your first tool, don’t trust them. It complicates things unnecessarily when there are plenty of ways to overcome the initial hurdle of bringing your ideas to life.
I didn’t start this project because I wanted to build a custom automation platform. I started this because we kept hitting the same wall: Why can’t I just make this behave a little differently? If you find yourself asking this question every other day, it’s usually a sign that you need something you own.
We needed three things: speed, reliability and the ability to see exactly what was happening and why. We also needed to know what was going on, when, and whether it was actually working. Standard tools had gotten us far, but this particular problem required something more customized.
I chose Clojure because it is the programming language that best reflects my way of thinking: small, composable pieces that move data through clear pipelines. And before anyone assumes that a small user community means a dilapidated ecosystem: that’s not the case. Every library I include was built by people who think carefully about software, and the whole thing runs on the JVM, one of the most battle-tested platforms around.
But the language is secondary. It’s the principle that matters: querying for new content, deduplicating it with what you’ve already posted, generating a payload and sending it to an API. Any language can do that.
This is how the new pipeline works
We call the system we built Daedalus internal and the functionality is uncomplicated.
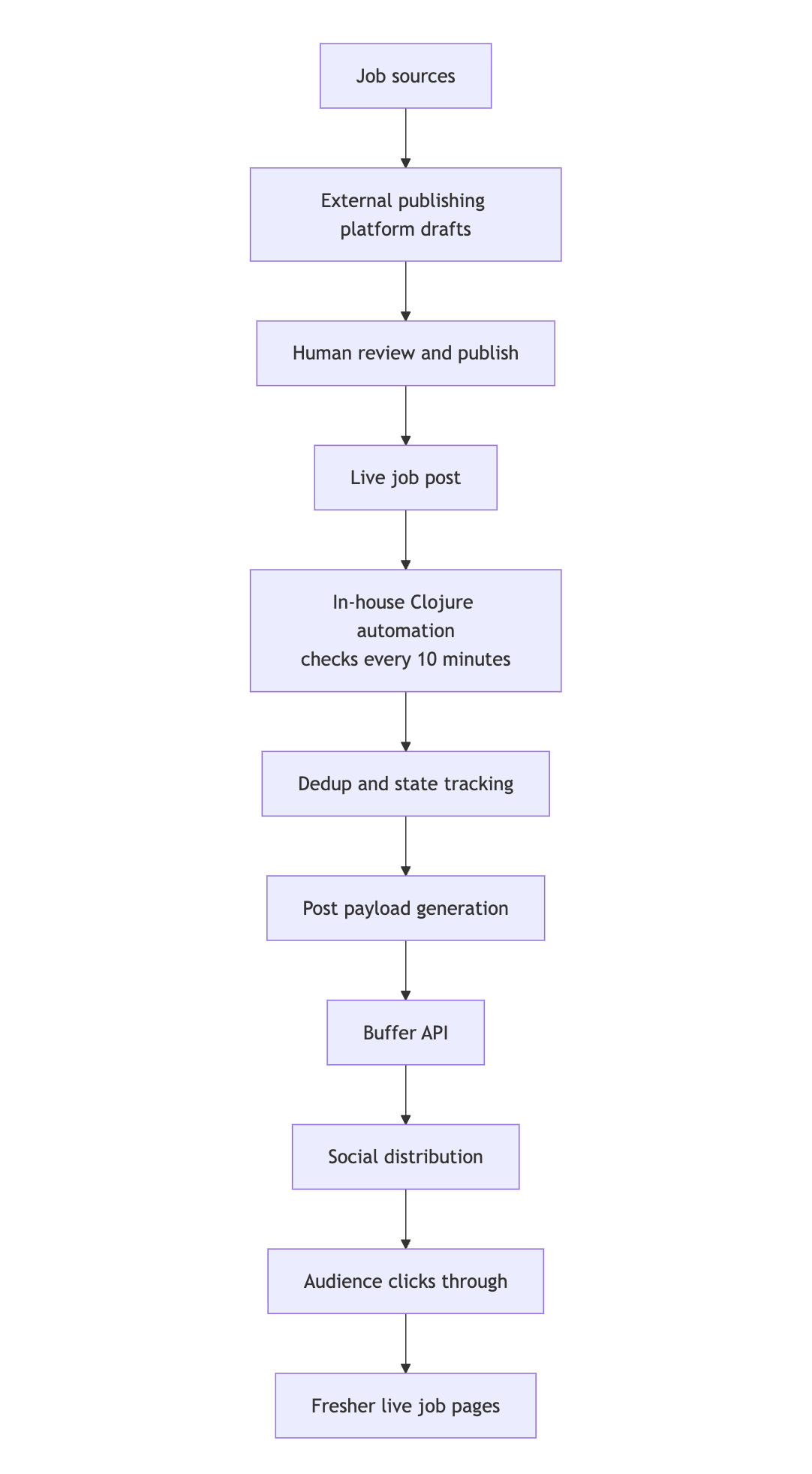
- Job offers are automatically imported as drafts into our publishing platform. A human reviews each one and publishes it; An editorial step remains intentionally manual. We want a person to decide what is worth promoting.
- From there, Daedalus asks for newly posted jobs every ten minutes from 8 a.m. to 10 p.m. Eastern time. We tried different time slots, and this is the sweet spot: it captures everything during active hours without overwhelming posting.
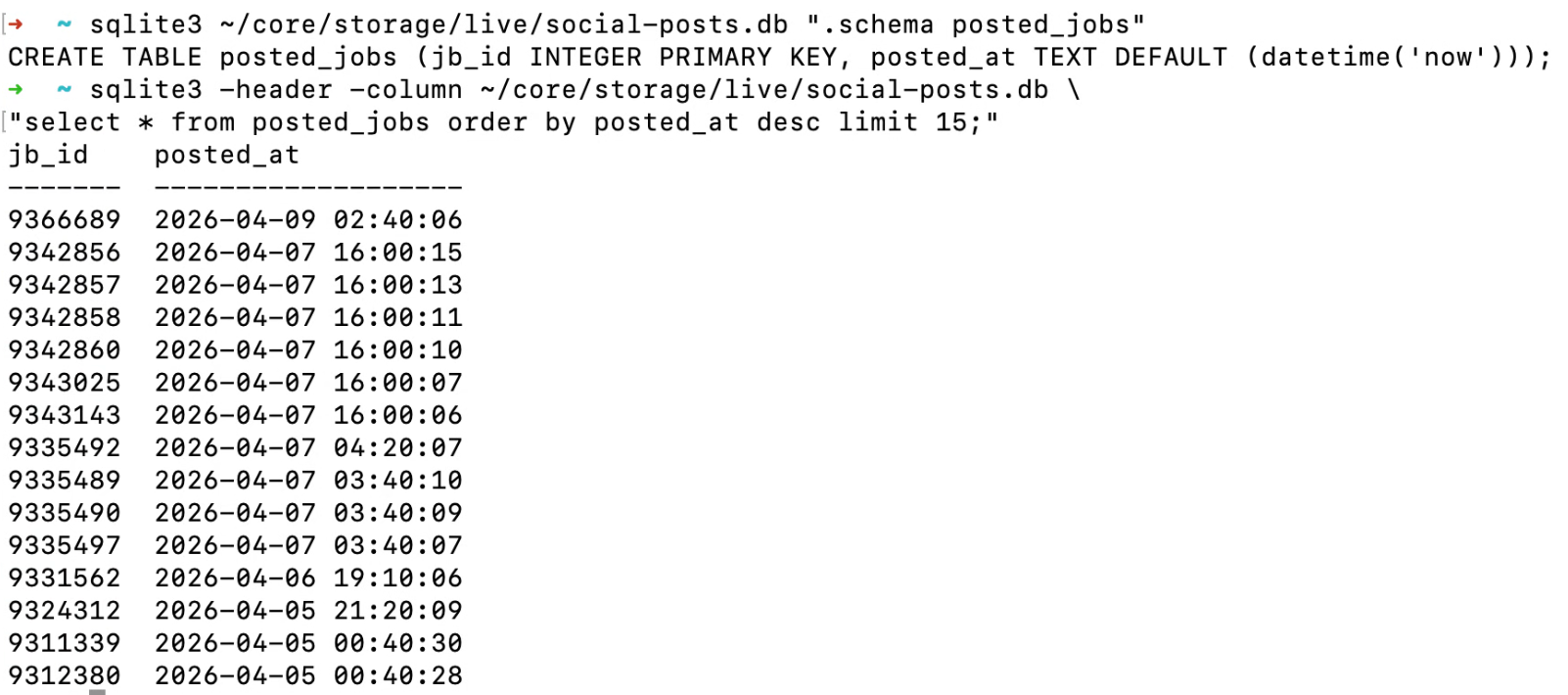
- When it finds something new, it checks it against an SQLite table before doing anything else. The scheme is as simple as it gets – a job ID and a timestamp. If we’ve already posted it, we’ll skip it. This keeps the system stateful and prevents duplicate contributions, even if the same order is accepted twice.
The post’s payload is intentionally simple: job title, company name, location and a link. Something like “Quality Assurance/Tester (REMOTE) – Koniag Government Services – Heart Butte, Montana, United States” followed by the URL.
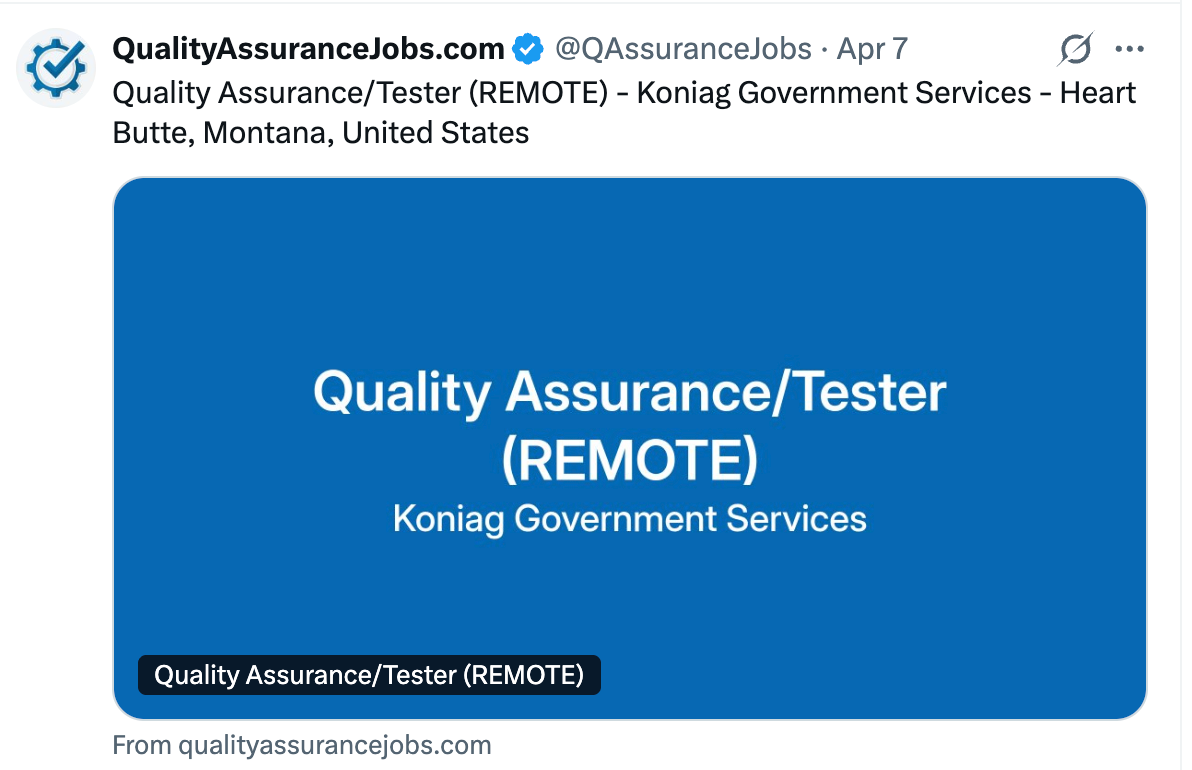
We stick to the essentials because when people figure out which jobs are worth applying for, they often need to be quick before doubling down on their applications. By presenting the right information immediately, they can decide more quickly what is worth their time.
This payload is forwarded to Buffer via GraphQL API using createPost mutation with addToQueue mode and auto-scheduling. Buffer takes the distribution time and sends it to X and Bluesky.

A note: Bluesky has been giving us some problems with generated attachments lately, so that’s on my to-do list.
What changed after the change
The transition occurred on March 19, 2026. At that point, Daedalus took over social distribution via the Buffer API on a unified schedule and we began measuring.
The numbers tell a more interesting story than a neat before and after anyway.
The clearest win was at On the site, job page views increased by 18.8%, total sessions increased by 11.4%, and active users grew by 13.6%. For a niche job board, this means that meaningful traffic leads to actual offers and not dead links.
Some key figures developed in the other direction. Total interactions fell by 15.2%, the number of new followers fell by 41.7%, and profile visits fell by 21.1%. That makes sense to me! We are a job board, not a personality brand. The goal was never to increase engagement numbers, but rather to get new listings in front of people more quickly. Range and freshness improved. We have optimized for this.
Posting volume increased from about 7.8 posts per day to about nine, a modest but intentional increase.
Operating profit is harder to chart, but is just as important. Before the switch, I spent almost ten hours a week maintaining the pipeline. After that, the weekly savings dropped to around three to five hours, and I can invest that time back into the community.
What we build next
The Buffer API was very useful for the core job posting pipeline, so we started extending the same architecture to a content marketing pipeline. We can run blog posts and newsletter content through the same detection-deduplication distribution pattern, with Buffer handling the social layer. We plan to send this automation live sometime in early May.
I have been in the software industry for a decade. I know what it feels like to be in between work – it’s the opposite of what most people would consider fun. The market is highly competitive and the job market is currently unsettled. I know this first hand.
This automation is important to my company because it is important to my community. I want smart and conscientious people to work. If QualityAssuranceJobs.com can do a better job by matching new jobs to the right people faster, then I’ll be happy.
Ready to build?
If you’re interested in trying out Buffer’s API, we have resources to get you started. Our developer docs cover the GraphQL schema, authentication flow, and quickstart examples. The Buffer MCP server documentation will guide you through connecting to Claude or another MCP-compatible AI agent.
If you need practical help, our support team is at your disposal. Alternatively, you can join our Discord server and chat with other people working with the API.
We’d love to hear what you do. Find us in Discord, or @buffer on all major social channels.
Follow us on Facebook | Twitter | YouTube
WPAP (697)
