
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
For years, SEOs have made a simple assumption: the more comprehensive your content is, the more likely it is to show up in AI-generated responses. In fact, every “best practice” in classic SEO content pushes you to do more: more subtopics, more sections, more words. Create the “Ultimate Guide.”
An analysis of 815,000 query-page pairs across 16,851 queries and 353,799 pages says otherwise:
- Fan-out reporting is almost irrelevant to citation rates.
- Two signals actually predict whether ChatGPT will cite your page.
- Six concrete changes to your existing content library will help.
1. The study
AirOps ran 16,851 queries over ChatGPT three times each across the UI, capturing every fan-out subquery, every URL searched, every quote made, and every page scraped. Oshen Davidson built the pipeline. I analyzed the data.
Each query generates an average of two fanout queries. ChatGPT fetches about 10 URLs per scan, reads through them, and then selects which URLs to cite. We evaluated how well each page’s H2-H4 subheadings matched these fanout queries using cosine similarity on bge-base-en-v1.5 embeds. We call this score Fan-out reporting: the proportion of subtopics that a page addresses at a similarity threshold of 0.80. (The similarity threshold of 0.80 was used to decide whether a subheading was considered a match to a fan-out query. Think of it like a relevance bar.)
The question: Are sites with higher fan-out coverage more frequently cited?
You can find even more information in the co-authored AirOps report.
2. Density barely moves the needle
In 815,484 lines, the connection between fan-out coverage and citation is weak.
Covering 100% of the subtopics yields 4.6 percentage points more than covering none. This gap becomes even smaller when you control for query match (how well the best heading on the page matches the original query). Among pages with strong query matches (>= 0.80 cosine similarity):
Moderate coverage (26-50%) outperforms comprehensive coverage. Pages that cover everything perform worse than pages that cover a quarter of the subtopics. The “ultimate guide” strategy produces worse results than a focused article that covers two to three related aspects well.
3. What actually predicts quotes
These two signals dominate: query rank and query match.
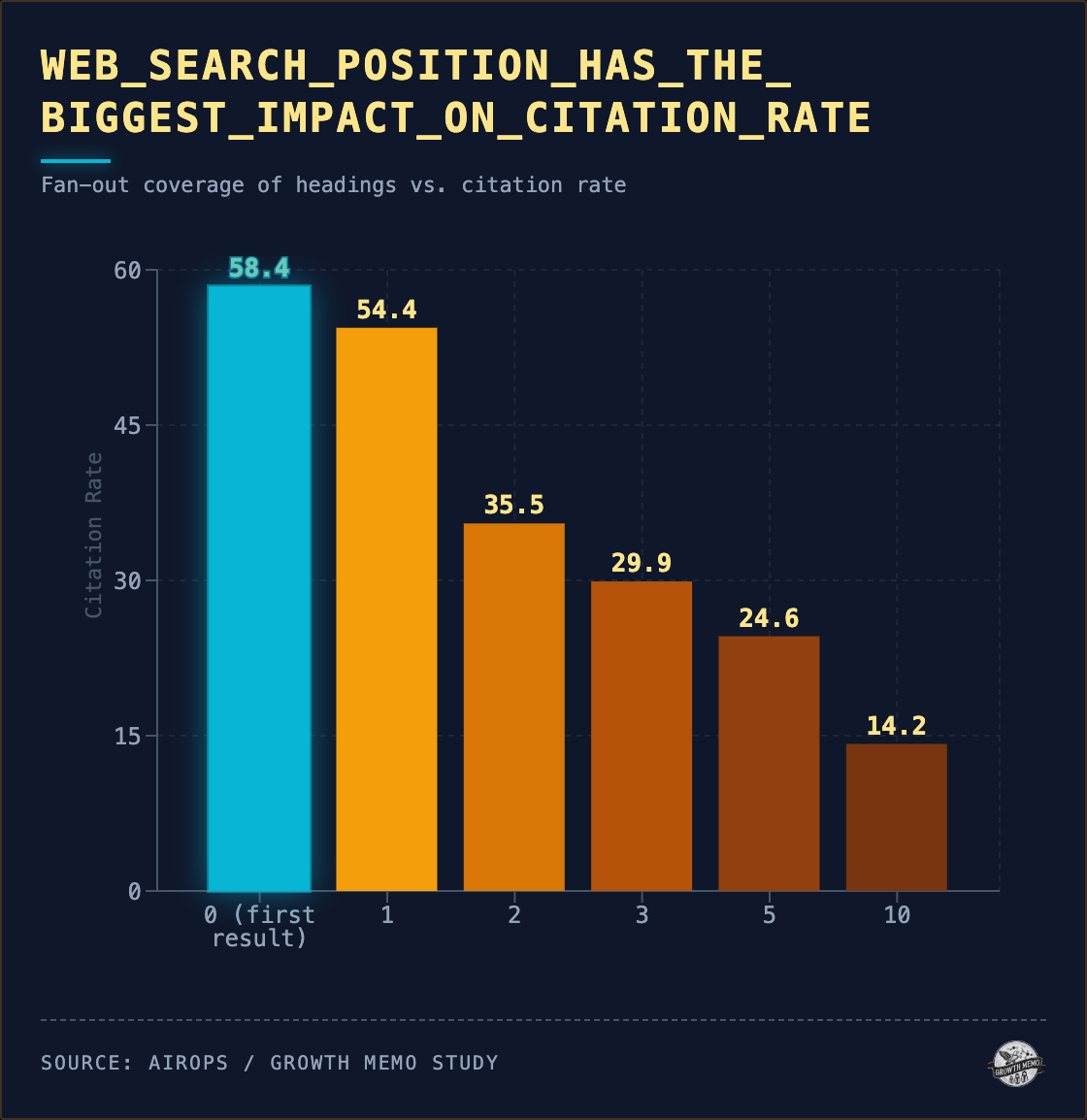
1. Retrieval rank is by far the strongest predictor. A page at position 0 in ChatGPT web search results (the first URL returned by the search tool) has a citation rate of 58%. Up to position 10 this value drops to 14%. For this analysis, we ran each prompt three times in a row, and the pages cited in all three runs have a median recall rank of 2.5. Pages never cited: medium rank 13.
2. Query matching (cosine similarity between the search query and the best heading on the page) is the strongest content signal. Pages with a heading match of 0.90+ have a citation rate of 41%, compared to 30% for pages below 0.50. Even for the top-ranked pages (positions 0-2), higher query match results in an increase of 19 percentage points.
Fan-out coverage, word count, heading count, domain authority: all secondary. Some are flat. Some are inversely correlated.
4. The Wikipedia exception
One site type breaks the pattern. Wikipedia has the worst recall rank in the dataset (median 24) and the lowest query match score (0.576). It still achieves the highest citation rate: 59%.
Wikipedia pages contain an average of 4,383 words, 31 lists and 6.6 tables. They are encyclopedic in the truest sense of the word. ChatGPT cites Wikipedia deep in search results where every other site type is ignored.
This is a density that acts as a signal, but on a scale that no publisher can reproduce. Wikipedia’s content is comprehensive, richly structured, and interconnected across millions of topics. A company blog post with 3,000 words and 15 subheadings is not the same.
5. The bimodal reality
58% of the pages retrieved by ChatGPT in this dataset are never cited. 25% are always quoted when they appear. Only 17% are in between.
The always cited and never cited groups look nearly identical across most content metrics: similar word counts (~2,200), similar number of headings (~20), similar readability scores (~12 FK grade), similar domain authority (~54). The on-page signals we measure do not distinguish between winners and losers.
What differentiates them is the polling rank. Pages that are always cited are ranked at the top when they appear. Pages that are never cited rank in the bottom half. The polling system is the gatekeeper regardless of what signals it uses internally. Everything else is a tiebreaker.
6. What this means for your content
Conventional wisdom when writing SEO content says to cover more subtopics, add more sections, and increase density. According to the data, the traditional approach results in “mixed” pages, with the 17% in the middle sometimes cited and sometimes ignored.
Mixed pages have the highest word count, most headings, and highest domain authority in the dataset. They are the “ultimate leaders.” They are also the least reliable performers in ChatGPT.
The sides that consistently win are focused. She:
- Adjust the search query directly in your headings,
- Tend to be shorter (the sweet spot for citations is 500-2,000 words) and
- Provide enough structure (7-20 subheadings) to structure the content without diluting it.
Create the page that provides the best answer to a question. Not the site that answers 20 adequately.
Featured image: Tero Vesalainen/Shutterstock; Paulo Bobita/Search Engine Journal
Follow us on Facebook | Twitter | YouTube
WPAP (907)
